Building Tanner: Context Engineering for Humans
A simple way to forecast the future is to look at what rich people have today. — Hal Varian
My todo list hit 100 items. So I started a new one. Before the week was out, that too was full. Inbox at 1,000+. Slack notifications glaring red. Docs to read, meetings to schedule, people to chase, links lost in the noise. This is modern work.
What is something execs, formula one drivers and venutral capitalists have in common? They have someone who helps them get things done. The rest of us got productivity systems. GTD. Inbox Zero. Pomodoro. We became our own project managers, optimising ourselves like machines. I’m good at capturing. Slack messages to myself, Obsidian brain dumps, todo lists spawning todo lists. Processing is where I fail. P0s get done because they scream. P2s slip quietly until they surprise me.
The Hal Varian rule holds. We, the people, too will have someone something. That time has arrived, if 2025 was the year of agents, 2026 is the years agents do stuff. I was exploring the Claude Agent SDK for reporting automation when I found Anthropic’s “Chief of Staff Agent” cookbook. I had to go off piste to get Tanner, my chief of staff agent, working the way I wanted. Here is what I learnt.
From Services to Agents
If you’ve built software in the last fifteen years, you’ve built services. Stateless endpoints. Request in, response out. The service doesn’t remember you, doesn’t decide what to do, it executes what it’s told. Service-oriented architecture gave us composability, but the composition was the design.
Agents invert this. An agent maintains state across interactions. It decides how to fulfil a request, not just whether to fulfil it. It evaluates trade-offs.
| Aspect | Services | Agents |
|---|---|---|
| State | Stateless | Persistent memory |
| Behaviour | Deterministic | Goal-oriented |
| Communication | Rigid API contracts | Semantic intent |
| Intelligence | Fixed rules | Dynamic reasoning |
“Most agent tasks are repetitive, narrowly-scoped operations. They don’t need the conversational breadth or the cost of a large model.” Ben Lorica
Ben describes an almost service-oriented architecture for small langugage models. The emerging pattern is a single capable model orchestrating specialised components. Not a committee of chatbots arguing with each other, one reasoning engine coordinating tools, memory, and execution. The orchestrator keeps things congruent, the magic is having subagents running asynchronously, trying to achieve the goals of the orchestrator. Each of them has a set of skills, tools & context (MCPs) available to them
Architecture
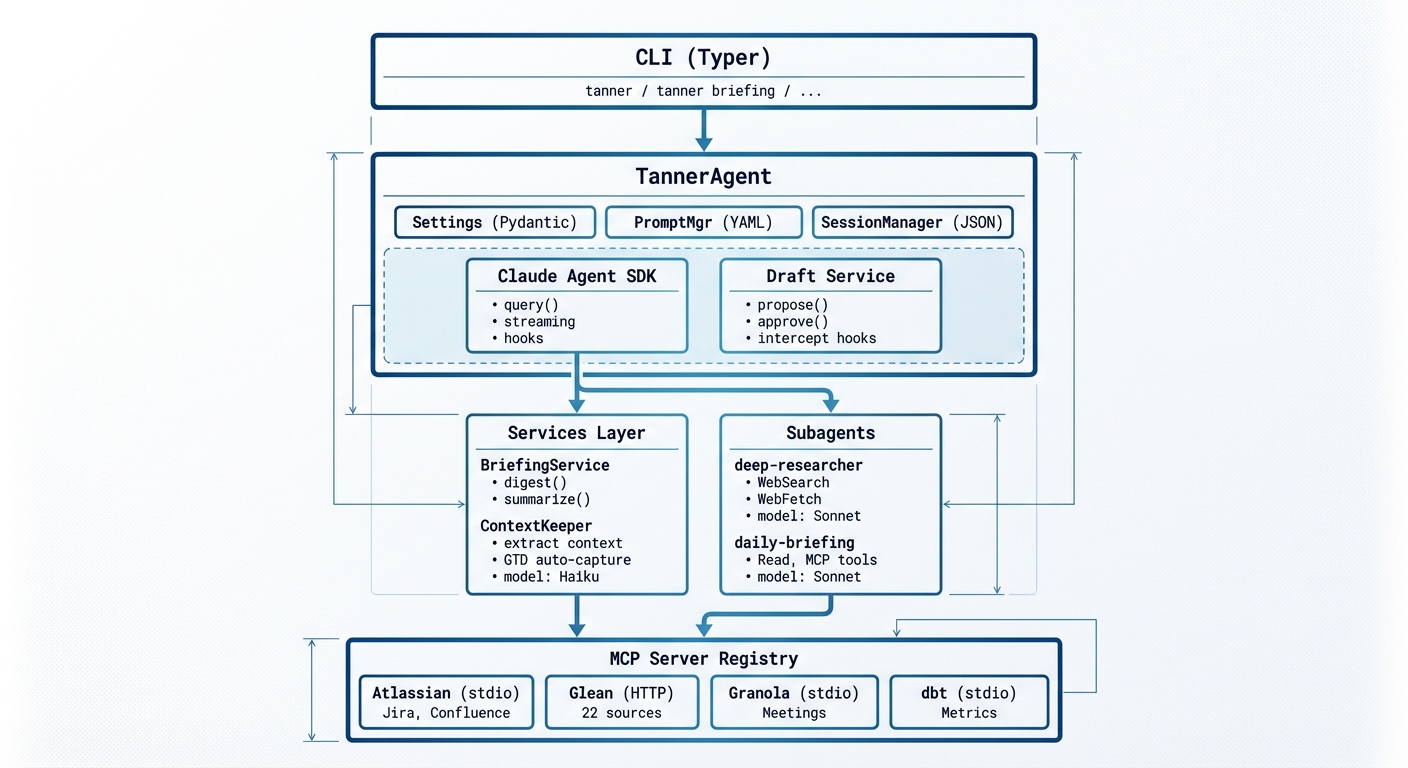
CLI at the top, MCP servers at the bottom. TannerAgent orchestrates. Settings, prompts, and sessions feed the Claude Agent SDK, which delegates to a services layer (BriefingService on Haiku, ContextKeeper for background extraction) and domain subagents (deep-researcher and daily-briefing on Sonnet). A lot of the agents have the ability to “write”, this gets risky, Tanner and myself review important things via hooks. Subagents are continously improved with new skills and functions & workflows (explicit ways of using tools). MCPs give you the protocol for the tools and the data needed to use them.
1. Natural Language First
No commands. Conversation.
“Help me get ready for the week ahead” and “remember to call the dentist” both work. A two-tier intent system handles this: keyword scoring for fast matching, Claude reasoning for ambiguous cases.
INTENT_KEYWORDS: dict[QueryIntent, list[str]] = {
QueryIntent.CALENDAR: ["calendar", "meeting", "schedule", "event", "free", "busy", "today"],
QueryIntent.JIRA: ["jira", "ticket", "issue", "sprint", "backlog", "epic", "blocker"],
QueryIntent.NOTES: ["notes", "granola", "transcript", "discussed"],
QueryIntent.GTD: ["task", "todo", "capture", "inbox", "next action", "someday"],
}
def detect_intent(query: str) -> QueryIntent | None:
query_lower = query.lower()
scores = {
intent: sum(1 for kw in keywords if kw in query_lower)
for intent, keywords in INTENT_KEYWORDS.items()
}
max_score = max(scores.values())
if max_score == 0:
return None # Fall through to Claude reasoning
return max(scores, key=scores.get)
The aim is to move to purely agentic reasoning but it’s slow. One work around was to introduce a scope parameter to the intent detection. Broad queries like “what’s going on?” scope:
Quick → Just your Jira tickets
Standard → Jira + recent meetings + GTD
Deep → All above + Slack threads + Confluence mentions
2. Skills as Markdown
The real investment came late in the development of Tanner. I had MCPs, services and subagents, but subagents were becoming bloated and I’m very particular about how I want things done. People who work with me are nodding violently. Skills solve this and I still don’t truly get how they’re so effective.
Tanner its self is simply a skill. A smart-router I give to Opus 4.5:
---
name: smart-router
description: Intent detection and routing
---
# Smart Router
You are Tanner, an intelligent Chief of Staff assistant...
## Intent Detection
When a user speaks to you, detect their intent:
### Task Capture
**Signals**: "remember", "capture", "I need to", "don't forget"
**Action**: Capture to GTD inbox using the GTDService
...
Skills like deep-research, meeting-prep, daily-digest, and coach-me each encode domain expertise. Adding a new capability means writing a markdown file.
It’s not just about efficiency. Actually, I would say it’s not about efficiency at all. The joy of LLMs, is they increase our ambition. The answer to “what’s possible” is now 100x more interesting. I have a lot of growth on the management side of things… the coach-me skill is helping. Every time I get leadership feedback or read something worth internalising, I add it to the skill definition. It becomes part of how Tanner talks to me. Read something good, feed it in, Tanner reflects it back in context. Getting the meta skill creator from Anthropic so you can keep adding to skills is massive, Tanner gets better everyday.
3. Persistent Context
The cookbook’s CLAUDE.md is static memory. Production needs dynamic context.
BriefingService assembles a situational briefing before Tanner responds to anything: GTD status, calendar, running session context.
class BriefingService:
def __init__(self, gtd: GTDService, calendar: CalendarService, sessions: SessionStore):
self.gtd = gtd
self.calendar = calendar
self.sessions = sessions
async def build(self, session_id: str | None = None) -> BriefingContext:
ctx = BriefingContext()
# Each source fails independently—always return *something*
with suppress(GTDError):
ctx.gtd = self.gtd.get_inbox_summary()
with suppress(CalendarError):
ctx.calendar = await self.calendar.get_today()
if session_id:
with suppress(SessionError):
ctx.session = self.sessions.get_context(session_id)
return ctx
Warm sessions skip redundant context—GTD and calendar are already in history:
async def build_for_turn(self, session_id: str, is_first_turn: bool) -> str:
if is_first_turn:
ctx = await self.build(session_id)
return ctx.format_full()
else:
# Only inject session-specific context on subsequent turns
ctx = await self.build(session_id)
return ctx.format_incremental()
This gets injected as a user message prefix, not system prompt. Cheaper, inspectable in logs, varies per turn without reinitialising the agent.
ContextKeeper extracts metadata after each turn: action items, decisions, topics, open questions, using Haiku in a background thread:
@dataclass
class ConversationContext:
session_id: str
action_items: list[ActionItem]
decisions: list[Decision]
topics: list[str] # Deduplicated, last 20
open_questions: list[str]
class ContextKeeper:
"""Extracts structured context from conversation turns using Haiku."""
EXTRACTION_PROMPT = """Extract from this conversation turn:
- Action items (who, what, when if mentioned)
- Decisions made
- Key topics discussed
- Open questions raised
Return JSON matching the ConversationContext schema."""
async def process_turn(self, user_msg: str, assistant_msg: str) -> None:
extraction = await self.client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=500,
messages=[{
"role": "user",
"content": f"{self.EXTRACTION_PROMPT}\n\nUser: {user_msg}\n\nAssistant: {assistant_msg}"
}]
)
self._merge_context(parse_extraction(extraction))
Session management was one of the elements I found most difficult as the complexity of the system grew. You need to be very intentional about how you implement sessions. You’ll start to notice missing context, or responses that don’t seem to comprehend what you’re saying. The nasty thing: it looks like it works. You get a response every time. Just the wrong one.
# WRONG: session_id created but never captured
async for message in query(prompt, options=options):
yield message # Streaming response, but session_id is lost
# RIGHT: capture session_id from init message
async for message in query(prompt, options=options):
if hasattr(message, 'subtype') and message.subtype == 'init':
self._session_id = message.session_id
yield message
# Next turn: resume the session
options = ClaudeAgentOptions(resume=self._session_id)
4. Subagent Delegation
The cookbook organises subagents by capability (financial-analyst, recruiter). Many architectures organise by data source (Snowflake agent, Jira agent). I organise by domain:
"deep-researcher": AgentDefinition(
description="Research tech blogs and arxiv papers",
tools=["WebFetch", "WebSearch", "Read"],
model="sonnet",
),
"daily-briefing": AgentDefinition(
description="Aggregate daily updates into leadership briefing",
tools=["Read", "mcp__devxp-toolbox__discover_tools", "mcp__devxp-toolbox__use_read_tool"],
model="sonnet",
),
“What have we discussed about the Q4 budget?” spans Granola transcripts, Jira tickets, Confluence pages, and emails. A domain subagent queries all of them. Data-source subagents would need dispatch logic, aggregation, and deduplication.
Data-source subagents make sense when many consumers query one source differently. I have one consumer, me, with many data needs. Domain wins.
5. MCP for Data
Context is king. We know this. If your company has Glean, it’s a game changer. Glean has access to knowledge documents, code, email, calendar events, and more. The statsig MCP for understanding ongoing experiments, dbt for understanding data and Granola for reading meeting transcripts, super charge what Tanner is capable of. Keeping MCPs in harmony with your skills and building “workflows”, i.e. a bunch of service calls chained together, worked well.
I do find MCPs to fail often. Health checks differentiate by type:
def _check_mcp_server_health(self, servers: dict[str, Any]) -> None:
for name, config in servers.items():
if config.get("type") == "http":
logger.debug(f"MCP '{name}' is HTTP-based, will validate at runtime")
continue
command = config.get("command")
if command:
command_path = shutil.which(command)
if not command_path:
logger.warning(f"MCP '{name}' command '{command}' not found in PATH")
6. Hooks Everywhere
The cookbook shows a compliance hook that logs Write operations. Useful. Production needs more:
def get_default_hooks(draft_service=None):
pre_hooks = [
log_tool_use,
validate_file_access, # Prevent path traversal
rate_limit_external_calls,
async_audit_log, # Fire-and-forget
async_metrics_collector, # Fire-and-forget
]
if draft_service is not None:
interceptor = create_draft_interceptor(draft_service)
pre_hooks.insert(0, interceptor)
return {
"PreToolUse": [{"matcher": "*", "hooks": pre_hooks}],
"PostToolUse": [{"matcher": "*", "hooks": [post_tool_log, async_post_audit_log]}],
}
Draft mode is the most important pattern. Side-effect tools, i.e. Jira updates and emails get intercepted at the hook layer. The agent proposes. You approve. Hooks are an unsung hero of the SDK.
SIDE_EFFECT_TOOLS = {"jira_create_issue", "jira_update_issue", "send_email", ...}
async def intercept_side_effects(tool_name, tool_input, tool_use_id):
if tool_name not in SIDE_EFFECT_TOOLS:
return {}
draft = draft_service.propose(
action_type=tool_to_action_type(tool_name),
content=generate_draft_content(tool_name, tool_input),
parameters=tool_input,
)
return {
"decision": "block",
"result": f"[Draft created: {draft.id[:8]}]\n"
f"Use 'tanner drafts approve {draft.id[:8]}' to execute."
}
7. Never Block
Anything non-critical to the response runs fire-and-forget. A chief of staff who makes you wait isn’t doing the job. I love having small agents running in the background, like a context ectraction daemon.
Context extraction uses Haiku (~$0.0005/turn vs ~$0.15 for Opus) in a daemon thread:
def run_context_extraction(u=user_input, r=response_text):
try:
asyncio.run(context_keeper_svc.process_turn(u, r))
except Exception as e:
logger.debug(f"Context extraction failed: {e}")
thread = threading.Thread(target=run_context_extraction, daemon=True)
thread.start()
Audit logging uses create_task with executor for file I/O:
async def async_audit_log(tool_name, tool_input, tool_use_id):
entry = {
"timestamp": datetime.now().isoformat(),
"event": "tool_use",
"tool_name": tool_name,
"input_keys": list(tool_input.keys()),
}
asyncio.create_task(_write_audit_entry(entry))
return {}
The pattern choice matters:
| Task | Pattern | Why |
|---|---|---|
| Context extraction | Daemon thread + sync API | Needs full turn pair, not triggered by tools |
| Audit logging | create_task + executor |
Triggered per tool, async-native |
| Metrics | create_task |
In-memory, no I/O blocking |
| Subagent work | SDK Task tool | Needs full context and tool access |
100 turns a day costs $0.05 for automatic GTD capture. The daemon thread dies when the program exits. No cleanup. If it fails, the user never notices.
The Invisible Craft
I’m very opinionated about the software I use. I 1000% agree with Patrick Collison’s quote about beauty being a signal of care. If the surface is well-crafted, the infrastructure is probably good too.
I invested heavily in Rich and trying to take as many lessons from Will McGugan in building terminal apps. I also invested in some whimsy.
- On exist, Tanner will drop some wisdom typical of a chief of staff (the GTD principles). (“The urgent will always crowd out the important. Don’t let it.”).
- Unicode status symbols (✓ ○ ◐ ⏳ →) scannable in a way words aren’t.
- Named panels (“Tanner” not “Response”). “Context briefing injected” in muted text—transparency without noise.
Some under the hood details that made things work smoothly:
- 5-minute token expiry buffer.
- Corrupt file resilience (skip with warning, don’t crash).
escape(item.title)prevents Rich markup injection.- Filesystem-safe session IDs.
- Lazy loading via properties.
- Semantic terminal colours that respect your theme.
Benn Stancil wrote that real magic comes from spending unreasonable time on something small. Claude Code in Ghostty feels mechanical. Not utilitarian. Mechanical. You feel the machinery working. That’s not absence of craft. It’s presence.
The Sharp Edges
No continual learning. Every session starts from baseline. State getting stale is the failure mode I think about most. Only skills evolve and context builds up.
I still read the originals. When Tanner summarises a document, I read the source. Partly trust calibration. Partly respect, someone chose their words (maybe). I don’t think the goal is to never read anything yourself.
I added features too fast. A million ideas in the first two weeks. Should have iterated on the main flows. But that’s not very me.
The Inversion
We’ve spent two years talking about context engineering for agents, how to give models the right information at the right time. Write, select, compress, isolate. Prevent context rot. Manage the window.
But humans have the same problem. Inbox at 1,000+. Todo lists spawning todo lists. We’re drowning in context too.
Tanner inverts this. It does context engineering for me. Surfaces what I’d miss. Filters the noise. Maintains continuity across conversations. The model manages my context window.
GTD’s insight was that your brain is for having ideas, not holding them. But you still had to do the processing; the weekly reviews, the clarifying, the “what’s the next action?” David Allen made you your own chief of staff.
Agents change this. The processing layer isn’t your job anymore.
Varian’s rule was about what rich people have. They had assistants who got stuff done, not organised, executed. The rest of us got productivity systems. We became our own project managers.
Now the agent handles that layer. The surfacing. The “what did I miss?” The continuity. Context engineering for humans.
The decisions are still mine. The doing might be too. But the processing? That’s Tanner’s job now.
If you’ve built something like this or you’re thinking about it I’d genuinely love to hear from you.